
浅谈运维工程师能力的培养
一、运维工程师发展路线
1. 传统运维
侧重点是解决具体的问题。要求具备扎实的底层的知识储备,如网络、linux、数据库、硬件设备调试、服务部署等。以及一定的故障处理能力和经验,能够快速解决问题,实施变更。能够处理突发故障,顺利完成服务的部署,变更的实施。
2. 云计算运维
侧重点是开源技术方案的使用,为云服务的稳定提供保证。随着业务不断发展,服务器规模扩大,就需要具备大规模服务器的批量管理能力。要求对开源技术解决方案有一定的掌握,主要面向基础运维平台建设,运维工具的开发,提高运维效率。硬件层面的资产管理。系统层面的管理例如vmware openstack虚拟化,以及docker k8s容器化。应用层面例如prometheus监控,elk日志,集群,数据库等开源服务管理。重点在于广泛使用开源技术保障服务的稳定,为项目的稳定运行提供保障。
3. DevOps
侧重点是开发运维平台,要求较高的开发能力。主要是管理应用的全生命周期,负责自动化运维平台的设计和开发,实现运维标准化、自动化、平台化。例如开发CMDB平台、作业平台、工单系统、告警平台等。以及充当业务开发与业务运维中间人的身份,从中发掘业务瓶颈并推动优化与改进。
4. SRE
侧重点是从业务角度提升运维质量。负责软件和系统的架构设计,运维流程的优化,让公司服务以及系统运行得更加可靠,更加稳定,扩展性更好,更能有效地利用计算机资源。要求技能包括算法,数据结构,编程能力,网络编程,分布式系统,架构设计,故障排除等能力。SRE重视开发,重视效率,追求自动化,专注于整个软件系统的生命周期管理。
需要明确的一点是DevOps 首先是一种文化,后期逐渐独立成一个职位,而SRE从一开始就明确是一个职位。DevOps更需要开发能力,而SRE更需要知识的广度。DevOps 工程师掌握相关技能之后,也有机会可以发展为 SRE 工程师。 而一位合格 SRE 工程师,在有选择情况下面,我相信不会去转型为 DevOps 工程师。
二、运维开发技能学习路线
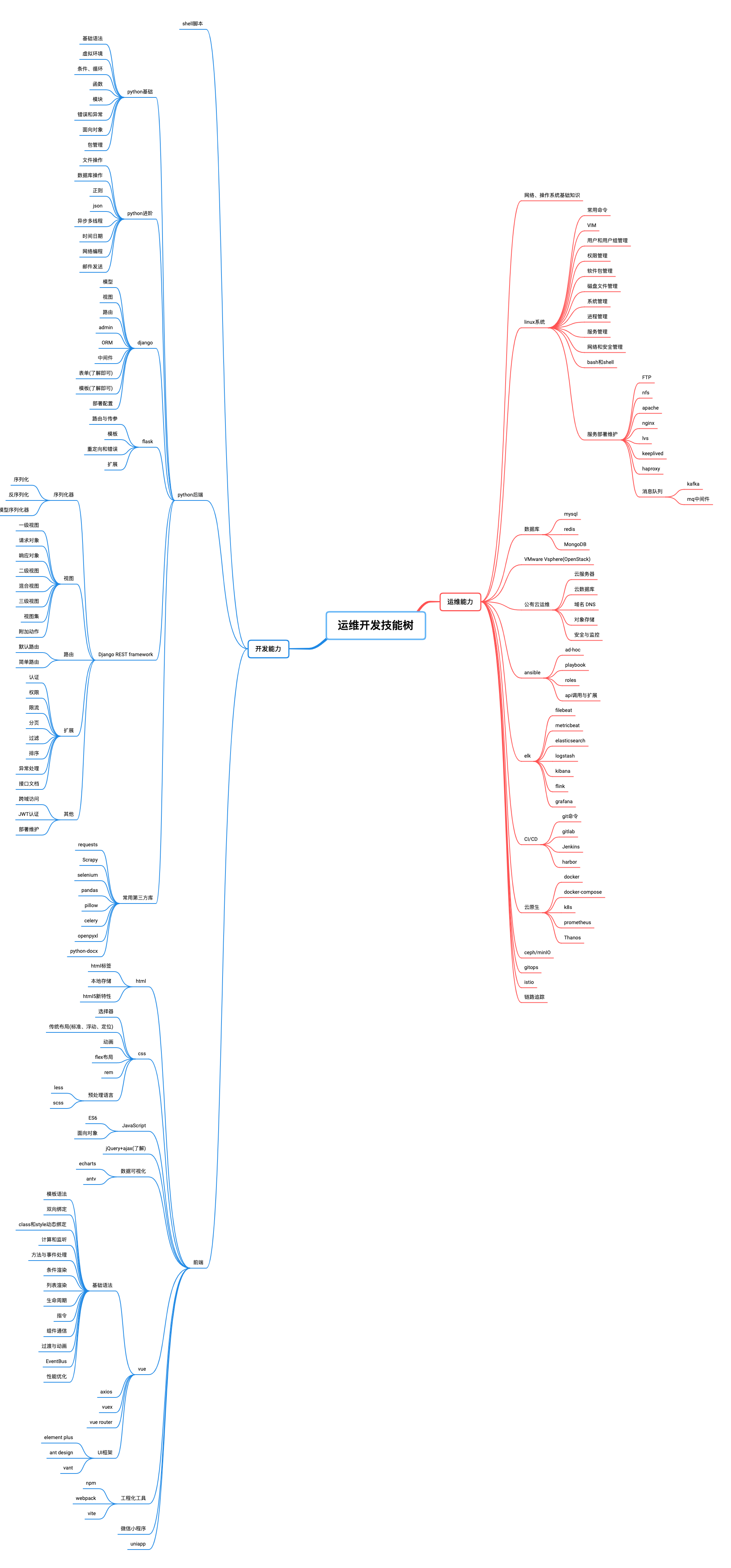
三、常见的运维开发项目案例
1. 公有云管理平台
项目背景
大型互联网公司出于成本、可靠性等因素,往往会购买多家云厂商产品提供服务。但在日常运维工作中,高频的操作往往也只是查看主机配置信息、当前机器状态、以及资源到期时间、服务器强制重启、CDN资源刷新、COS存储查看、日志下载等操作。
可以根据上述需求,开发一套公有云管理平台。将所有资源列表形式展现出来,配置信息、当前状态、到期时间等关键内容直观展现出来,并使用标签的方式,实现资产的便捷筛选。
只授予开发人员常用操作,例如CDN刷新,日志下载,COS存储查询等操作权限,避免登录云服务器控制台误操作情况发生。
项目亮点
使用腾讯云、阿里云、华为云等公有云厂商sdk,实现资产信息的查询等高频操作
使用celery实现信息异步定时更新入库
用户权限管理,开发人员和运维人员权限分离
使用antv-g6实现资产树结构
使用echarts将资产统计信息可视化展示
2. CMDB
项目背景
企业中IT资源种类繁多(机房、服务器、存储设备、网络设备、项目业务划分等)且需要频繁更新,传统的excel表格维护更新方式已不能满足需求。此时就需要通过开发资产管理系统,实现资产的自动发现和信息同步更新,保证数据的准确和一致性。除此之外还开放API接口与现有的运维体系结合,为作业系统、工单系统等平台提高IT数据支撑。
项目亮点
由于资产的字段,对应关系频繁更改,传统的关系型数据库已无法满足需求。通常采用MongoDB存储数据。使用mongoengine库完成数据库的操作。
使用ansible的API接口调用setup模块抓取服务器硬件信息,支持手动同步和定时同步信息。
也可以使用shell脚本或者go开发exporter,定期向cmdb接口上报服务器信息。
提供动态 Inventory 清单接口,方便ansible调用执行批量化操作。
提供完善的资产信息、模型、对应关系增删改查接口,方便其他工具平台调用。
3. 作业平台
项目背景
面对批量管理主机的需求,已有成熟的ansible,以及web工具Tower,但是缺乏现成的API接口,无法与现有的自动化运维平台直接调用。
随着服务器规模增多,存在大量的定时同步、备份、清理等任务脚本。需要集中化管理定时任务,并对任务执行情况一目了然。
当进行服务批量部署、软件包批量更新时,具备批量文件传输的能力。
记录所有通过作业平台页面或者API调用的操作记录,提供任务重试和历史记录查询的功能。
项目亮点
将常用自动化操作(例如给开发人员创建普通用户账户设置权限、常见服务部署、配置文件更新等操作)提前编写playbook。当需要执行常用自动化操作时,调用CMDB接口获取动态主机清单,并在前端传入相关变量参数,完成playbook变量替换,使用ansible执行playbook,完成相关的自动化操作。
使用对象存储或者ansible所在服务器本地目录,实现文件上传功能。存放常用shell脚本、需要批量分发的文件,便于ansible调用相关文件执行自动化操作。
开发定时任务管理模块,使用异步多线程执行。支持任务结果查询验证功能,实现定时任务的统一集中化管理。
开放提供API接口,支持传参调用执行批量任务并返回执行结果。
4. 工单系统
项目背景
在公司内部,项目上线、配置变更、调整权限等操作,往往都按照运维管理制度,依次由负责人审批,通过后再执行相关具体操作。传统的资源申请基本是通过邮件,存在沟通成本高,消息处理不及时的问题,且出现问题后回溯麻烦。
开发一套工单系统,可以将运维平台各个自动化程序组件相关联打通,可以极大的规范内部管理流程,提升沟通及管理效率。
项目亮点
与公司内部邮箱或通讯软件集成,实现每步流程申请人和相关审批人邮件或消息通知。
与钉钉或企业微信的用户列表集成,避免人员流动时频繁手动更新维护数据。
与作业平台集成,当领导完成审批后,直接调用作业平台API,执行一系列自动化的操作。
在前端使用流程图方式展示整个操作的完成流程,以及当前完成进度。
5. 告警平台
项目背景
为了保障业务稳定,通常会采用多种监控服务实现告警通知,但通常都存在告警复杂而凌乱,无法将告警信息进行灵活分类,缺乏统一管理的能力。这样就加大了运维人员对告警信息的判断难度,进而无法快速的的定位到根因,也就无法快速的解决问题。
传统的告警配置,告警通知人员/通知组,告警等级在创建告警时已配置,不具备灵活将告警内容通知至值班人员和告警长期未处理,告警严重性等级提升的功能。
项目亮点
告警统一收集汇总。将现有的Alertmanager、grafana、kibana、以及其他的脚本告警统一收集展示,方便运维人员清楚知道当前系统存在的问题。并提供历史告警查询功能,便于分析当前容易产生的告警,促使不断优化改进,降低告警产生。
灵活的分配策略。根据不同的应用,选定不同的筛选条件,将条件相结合,让指定的告警通知到特定的人。并于现有的值班系统相结合,使每条告警按不同的告警等级以微信、邮件、短信、电话的方式通知到值班人员和第一负责人。
当告警在指定的时间段内未恢复时,启动告警升级策略。将告警通知至第二负责人,以此类推。
与工单系统集成,自动将告警事件指派给对应负责人,并创建工单提示负责人及时处理故障。
6. 应用发布系统
项目背景
应用发布系统使用现有的Jenkins发布平台或者Gitlab CI均可。但是缺乏与现有的运维平台建立连接的能力。理想的应用发布系统应当是当开发人员提交申请单,领导审批完成触发自动更新操作,从发起到结束形成闭环。可以利用Jira、Gitlab的webhook功能,以及Jenkins插件的灵活性,实现应用发布系统与工单系统的紧密结合。为项目的敏捷开发、快速迭代提供运维保障支撑。
项目亮点
与工单系统紧密结合。当开发人员完成新功能开发后,只需在工单系统提交新版本上线流程。待领导审批后,执行自动化部署操作。
与Jenkins紧密结合。通过webhook自动化完成分支更改、部署发布流程,减轻人工运维操作工作量。
与CMDB紧密结合。当完成版本发布后,自动更新相关记录。
四、运维平台案例参考
1. 蓝鲸智云平台
2. spug
https://spug.cc/docs/about-spug/
3.CODO
https://github.com/opendevops-cn/opendevops
五、常见运维场景自动化思路
1. 新建资源

2. 发布流程

3. 配置变更

4. 故障处理

六、学习资料视频推荐
1. python后端
python菜鸟教程(适合有一定开发基础,直接查看文档,节省时间)
https://www.runoob.com/python3/python3-tutorial.html
python黑马程序员视频(适合从0开始学习入门)
https://yun.itheima.com/course/542.html
django视频教程(主要学会url view models admin)
https://www.bilibili.com/video/BV1jx41197Qv?p=1
django文章专利(目前已知国内研究django最深入的博主了)
https://pythondjango.cn/django/basic-tutorials
flask教程(学会了django后,学习flask直接参考文档即可)
https://www.cainiaojc.com/flask/
DRF视频教程(学完DRF基础知识后,跟着老师做一个项目,就可以完全掌握了)
https://space.bilibili.com/481846903
request爬虫(根据实际需求,网上现查即可,如果想系统学习,推荐购买书籍)
https://item.jd.com/13527222.html
2. 前端
html css视频教程(黑马的pink前端必须强烈推荐)
https://www.bilibili.com/video/BV14J4114768?p=1
JavaScript视频教程(推荐李南江,自带二倍速的男人)
https://www.bilibili.com/video/BV1rt4y1Q7wo?p=1
jQuery+ajax(了解即可,现在基本都是前后端分离开发)
https://www.bilibili.com/video/BV17W41137jn?p=1
echarts数据可视化(还是推荐黑马的pink)
https://www.bilibili.com/video/BV1v7411R7mp?p=1
vue视频教程(还是建议大家多看官方文档,毕竟国人写的,还是很容易理解)
https://www.bilibili.com/video/BV1Zy4y1K7SH?p=1
vue2 PC端项目实战(适合新人入门,代码并没有高度组件化)
https://www.bilibili.com/video/BV1eh411d7zD?p=1
vue3 手机端项目实战(接近实际项目开发,强烈推荐)
https://www.bilibili.com/video/BV1YK4y1W7k5?p=1
微信小程序(微信小程序入门较为简单,主要参考官方文档即可)
https://www.bilibili.com/video/BV1WP4y137EE
七、运维思考
1. 如何从0开始实现运维自动化
梳理目前手头的工作,你会发现其中有一半的运维工作都存在重复性,或者满足某些特定场景条件下触发,且每次操作的步骤基本相同,存在较少的意外情况发生。那么就对这些常见问题进行分类和梳理,考虑能否将这些工作内容改造成自动化操作。起步初期不一定需要做多么完善的平台出来,可以先着手于解决实际运维工作中的一个个具体的实际小问题,并听取其他同事的意见,帮助他们开发特定场景需求下的自动化工具,积累开发经验。先从最基本的操作自动化做起,逐步拓展到特定场景下的自动化处理,再到最后实现智能化运维。
运维自动化不是一蹴而就的,他是一个漫长的逐步演进的过程。通常都是遵循这样的演变:运维人员手动支撑 => 运维标准规范化 => 运维工具化 => 平台自自动化。
2. 运维自动化与运维标准
要想解决运维自动化的问题,前提是在运维团队内部已形成运维标准化/规范化。试想一下,如果同样的一个nginx服务,由不同的人操作部署。由于每个人操作习惯不同,且没有运维标准,必然会导致服务的部署方式、部署目录、启动用户五花八门。当你想开发一个工具管理所有nginx服务时,你会发现,有半数的工作量是要编写一堆if条件判断,来适配各种各样的环境目录问题。
因此,要想实现运维自动化的首要条件是避免差异性,实现环境的统一。因为团队中每个人的习惯不同,没有规范必将导致服务器配置差异,这将在无形中大大增加了运维的难度。只有实现了运维标准规范化,才能为后续的自动化打下坚实的基础。
但是需要注意的是,在运维标准的实践过程中,标准的制定很容易,但是人为执行起来却很难。因此,在规范制定之时,应该要满足大多数人的风格习惯,制定的规则简明扼要,不要让理解规则成为负担,最后是需要运维团队每个人需要明确规范的目的,让运维规范成为大家的共识。才能让每个人在以后的运维工作严格的按规范去执行、不断的进行优化改进,为自动化运维打下坚实的基础。
3. 运维思路转变
纵观整个IT技术岗位,运维人员应该算是最为“苦逼”的一波人了,没有经历过半夜被故障告警电话吵醒、通宵实施变更的运维职业生涯是不完整的。但是公司的管理者往往有些对技术了解并不深入。无论是出现网站访问缓慢,还是系统各种错误,管理层首先想到的第一件事就是找运维这个“救火员”。从一定意义上讲,保障业务的稳定运行是运维人员的基本岗位职责,但是不排除很多情况下是因为开发人员代码质量低,导致运行出现问题,然而有些开发人员未经自查便得出结论,是系统环境的问题,所以运维充当“背黑锅”是常事。不仅要承担别人犯下的错误,还要拼死拼活地去解决可能非自身原因造成的问题。
但是随着IT规模越来越大、系统越来越复杂,以故障事件驱动的“救火员”,依靠人工检查处理的工作方式,不仅会让自己的工作被动,还效率低下。而且随着最近几年各家公有云厂商产品不断完善,云计算对于运维人员来说,既是机遇,也是挑战。一方面,云计算使得运维门槛越来越低,运维人员不再需要关注机房、硬件、网络、系统这些底层的技术保障,只需要在控制台web页面点点鼠标就能完成日常的运维操作,遇到疑难问题也只需要提交客服工单即可解决,但是只会提交工单的运维又怎么能为企业带来更高的价值呢?
基于以上原因,自动化运维应运而生。自动化运维的基本目标解决的是“能程序完成的事情尽量不要用人去干”,具体来说就是把周期性、重复性、规律性的工作都交给工具去做,最终达到提升运维效率的目的。简单来说,就是运维思路的转变,不再像以往那样仅仅是保证服务的正常稳定运行,出现故障能第一时间修复的这种以事件为驱动的运维工作。而是要让自己的精力从底层简单的日常运维工作中解放出来,做一些更具价值的事,以建设一套完善的自动化的运维体系为目标,充分发挥自己的核心竞争力,毕竟没有哪个开发能比运维更懂运维自动化产品的需求。在运维自动化建设中,每个运维人员即是优秀的产品经理,也是产品的开发者和使用者。



